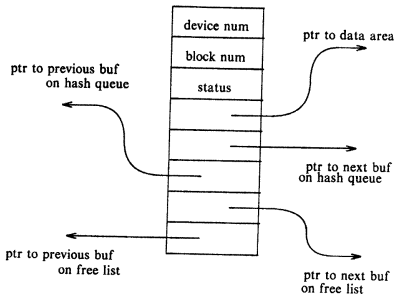
ADVANTAGES AND DISADVANTAGES OF BUFFER CACHE

ADVANTAGES
- The use of buffers allows uniform disk access. It simplifies system design.
- The system places no data alignment restrictions on user processes doing I/O. By copying data from user buffers to system buffers (and vice versa), the kernel eliminates the need for special alignment of user buffers, making user programs simpler and more portable.
- Use of the buffer cache can reduce the amount of disk traffic, thereby increasing overall system throughput and decreasing response time.
- The buffer algorithms help insure file system integrity.
DISADVANTAGES
- Since the kernel does not immediately write data to the disk for a delayed write, the system is vulnerable to crashes that leave disk data in an incorrect state.
- Use of the buffer cache requires an extra data copy when reading and writing to and from user processes. When transmitting large amounts of data, the extra copy slows down performance.